
Nạn đánh cắp nội dung website hay còn gọi là web scraping đang ngày càng mở rộng trên môi trường internet hiện nay. Rất nhiều chủ website phải đau đầu vì bao nhiêu công sức và chất xám của họ bỏ ra lại bị người khác đánh cắp và thậm chí còn lên top hơn website gốc nhờ nội dung đó. Hôm nay, Lucid Gen sẽ chia sẻ với các bạn một vài mẹo để ngăn chặn việc đánh cắp nội dung website, khiến cho kẻ trộm phải ngán ngẩm và muốn từ bỏ.
Bạn cần đọc trước khi quyết định
Ban đầu khi bị đánh cắp nội dung website, bạn thường sẽ nóng lòng tìm cách ngăn chặn triệt để. Nhưng bạn nên biết “triệt để” là không thể. Bạn hãy đọc qua các nội dung dưới đây để hiểu bản chất của vấn đề và chọn phương hướng hành động phù hợp.
Web scraping là gì?
Web scraping là quá trình thu thập và trích xuất dữ liệu từ một website cụ thể, nhằm phục vụ cho các mục đích của người sử công cụ này. Các mục đích tốt thường là để nắm bắt thông tin, tuy nhiên có nhiều người xấu đã lợi dụng cách này để đánh cắp nội dung website của người khác.
Công việc này được các web scraping bot thực hiện liên tục từng ngày, giờ, phút để nhanh chóng phát hiện ra nội dung mới nhất và mang chúng về cho người sử dụng. Người dùng bình thường khó phát hiện ra scraping bot này, nhưng hãy yên tâm, Lucid Gen sẽ chỉ cho bạn cách nhận diện ra chúng.
Vì sao họ lại đánh cắp nội dung website của bạn?
Có rất nhiều lý do, nhưng phổ biến nhất chính là “không muốn làm mà muốn có ăn”. Muốn có traffic nhưng lười động não viết bài, không tiền thuê nhân viên content xịn nên họ đánh cắp chất xám của người khác cho nhanh.
Kiểu thứ 2 là đi học các “thầy” dạy mấy khóa học kiếm tiền bằng “Auto blog”. Nói thẳng ra là tạo một cái website rồi cài một vài plugin đi đánh cắp nội dung bài viết của các website khác rồi chờ có tiền từ Adsense. Mà mấy thầy ở Việt Nam thì các bạn biết rồi, giàu thật thì để dòng họ các thầy ăn còn không đủ, các thầy chỉ dạy những cách làm giàu đã sắp hết thời thôi. Bạn nào mà thấy mấy khóa này thì bỏ đi để làm người nha, không dễ ăn vậy đâu bạn ạ.
Còn một số kiểu khác nữa. Mà các bạn yên tâm, cái kết thường không tốt đẹp gì đâu. Một cái website chuyên đi cóp nhặt nội dung của website khác thì Google sẽ đánh giá nó rất thấp, có khi cũng chẳng duyệt Adsense. Cóp nhặt lâu ngày thì trở thành thói quen, về sau họ cũng không sáng tạo được gì, mãi đi sau bạn thôi.
Họ đánh cắp bằng cách nào?
Theo Lucid Gen tìm hiểu thì hiện nay 3 kiểu đánh cắp nội dung website phổ biến. Mình sẽ sắp theo thứ tự từ dễ ngăn chặn đến khó ngăn chặn nhất nhé.
Đánh cắp nội dung bằng RSS
Các web scraping bot sẽ truy cập vào các RSS của bạn để phát hiện ra bài viết mới nhất. Sau đó nó sẽ đi đến bài viết mới đó để trích xuất nội dung trên website của bạn rồi đem về máy chủ của nó. Các RSS thường có dạng như sau:
https://domain.com/feed(WordPress là dạng này)https://domain.com/feedshttps://domain.com/rss
Đối với dạng đánh cắp nội dung website này thì rất dễ ngăn chặn, bạn chỉ cần trì hoãn cập nhật RSS và chặn IP của các web scraping bot là ổn rồi. Cụ thể hơn thì Lucid Gen sẽ làm rõ ở phần dưới nhé.
Đánh cắp nội dung bằng HTML
Các web scraping bot sẽ truy cập vào trang blog và danh mục bài viết của bạn rồi phân tích HTML để phát hiện ra bài viết mới.
Đối với dạng đánh cắp nội dung website này, các web scraping bot không truy cập các RSS nên chúng ta sẽ khó phát hiện ra chúng hơn. Nhưng cũng có cách, Lucid Gen sẽ nói rõ hơn trong phần giải pháp ngăn chặn nhé.
Đánh cắp nội dung thủ công
Dạng này thì kẻ trộm nội dung website có tính “cần cù bù siêng năng” hơn, họ sẽ đi “Copy Paste” bằng tay. Gặp dạng này thì không thể ngăn chặn bằng công cụ được. Chỉ có một cách là bạn phải “cần cù” hơn kẻ trộm, thêm nhiều liên kết nội bộ, chèn watermark vào ảnh, sử dụng tên riêng nhiều hơn…
Việc sửa nội dung, sửa tên, xóa liên kết thì dễ với họ (có khi chúng quên sửa luôn), nhưng tạo lại hình ảnh phù hợp với nội dung mà không có watermark thì sẽ khó khăn với chúng.
Lợi ích tiềm ẩn khi bị đánh cắp nội dung
Lucid Gen muốn chia sẻ với bạn một cách nhìn khác về vấn đề này. Trong nhiều trường hợp, việc bị đánh cắp nội dung cũng mang lại lợi ích cho website gốc đấy nhé.
Google đánh giá cao website của bạn
Một website mà được các webstie khác sao chép lại nội dung thì chắc chắn website đó có nội dung hay, có giá trị cho người dùng. Google dư sức biết được đâu là bài viết gốc, đâu là trang sao chép lại nội dung. Vậy nên, nếu như họ đánh cắp nội dung website của bạn mà họ không giành được vị trí xếp hạng của bạn thì cũng đừng quá lo lắng.
Hãy theo dõi thêm một thời gian, cứ cho họ đánh cắp đi, đến khi nào bạn thấy có dấu hiệu giành vị trí xếp hạng với bạn rồi thì hành động. Bạn hãy tưởng tượng 30-50% nội dung website của họ là sao chép từ bạn, bạn hành động một lần làm họ mất sạch 30-50% đó luôn thì sướng hơn là chỉ 1-2 bài đúng không.
Nhận được backlink từ đối thủ
Một số nơi sao chép nội dung nhưng vẫn giữ nguyên các liên kết nội bộ của bạn, có thể họ quên xóa hoặc cố tình để lại cho đẹp lòng nhau. Thế là bạn vô tình được tăng thêm backlink rồi.
Nếu như họ không mang lại backlink cho website của bạn, bạn hãy thử gửi yêu cầu chèn link bài viết gốc của bạn vào website của họ. Nếu họ đồng ý thì bạn có backlink, nếu họ không đồng ý thì chúng ta sẽ hành động.
Có nên dùng plugin chống sao chép thủ công?
Theo quan điểm của Lucid Gen thì không nên. Vì nhiều lý do như sau:
- 99% traffic của bạn là người dùng bình thường, chỉ có 1% là kẻ trôm thủ công thôi. Bạn đừng vì 1% này mà làm khó 99% người dùng còn lại. Đôi khi người ta cần sao chép nội dung, hình ảnh từ website của bạn cho mục đích tốt hơn như học thuật, chỉ dẫn cho bạn bè…
- Bản thân Lucid Gen cũng cảm thấy khó ưa khi vào mấy trang không cho sao chép, không có click chuột phải. Mình có cảm giác là chủ của các website này hơi ít kỷ.
- Chỉ cần cài một tiện ích như Enable Copy là có thể dễ dàng vô hiêu hóa tính năng cấm sao chép rồi. Dân thường thì không biết chứ dân chuyên đi trộm nội dung thì biết hết trơn rồi bạn.
- Làm nặng website của bạn thêm.
Vậy nên bạn khỏi cài mấy cái plugin chặn sao chép nội dung nha. Không có tác dụng với kẻ trộm đâu, chỉ làm người dùng khó chịu thôi à.
Cách ngăn chặn việc đánh cắp nội dung website
Lướt qua phần trên chắc bạn đã hiểu vấn đề đánh cắp nội dung website là như thế nào. Vấn đề này ảnh hưởng nghiêm trọng đến website của bạn ở mức độ nào thì hãy chọn giải pháp phù hợp theo mức độ đó. Hoặc tốt nhất là sử dụng cùng lúc tất cả giải pháp luôn nhé.
Lucid Gen khẳng định rằng, tuy không thể giúp bạn xử lý “triệt để” vấn đề này. Nhưng nếu bạn áp dụng tất cả biện pháp dưới đây thì chắc chắn nạn đánh cắp nội dung website sẽ giảm với website của bạn. Nếu có biện pháp hiệu quả mới thì mình sẽ cập nhật thêm vào bài viết này.
Chặn IP của web scraping bot
Để làm được cách này thì bạn phải sử dụng Wordfence Premium. Chúng ta sẽ nhờ Wordfence ghi chép lại lịch sử IP, Hostname và User-agent đã truy cập vào website của bạn. Từ đó lọc ra các web scraping bot để chặn chúng.
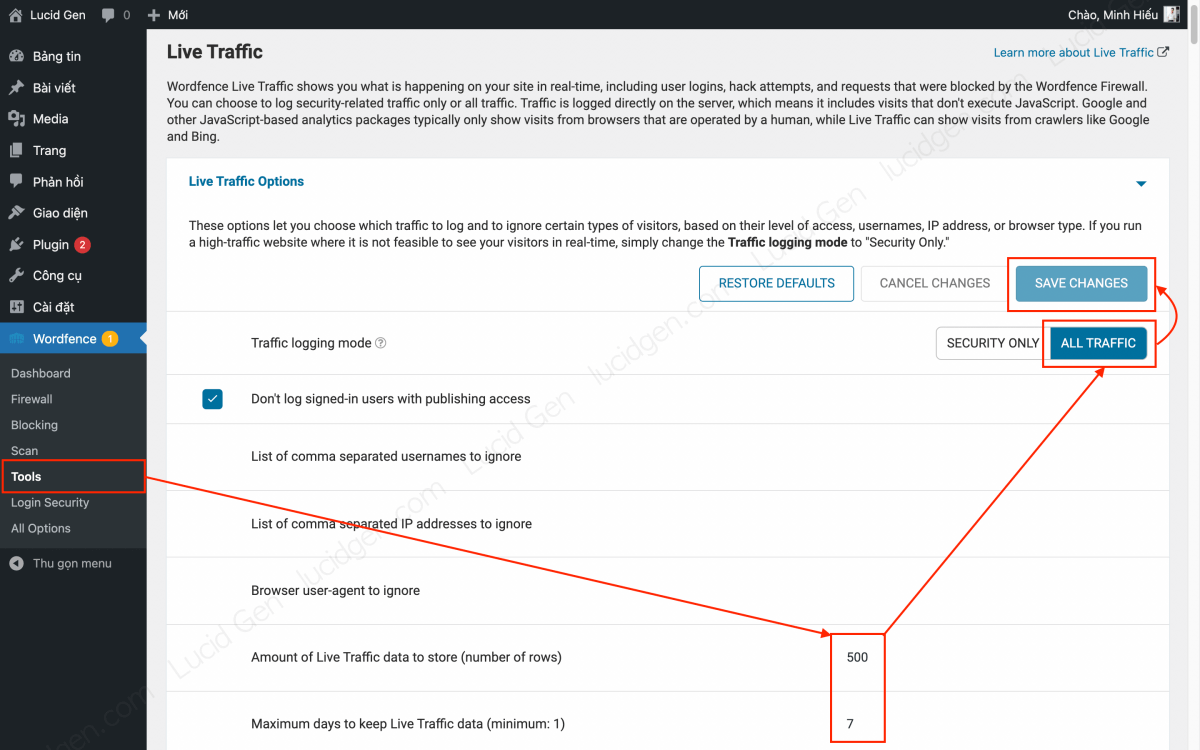
Bước 1: Bạn cài đặt chế độ Live Traffic. Bạn vào Wordfence > Tools rồi cài đặt như sau.
- Amount of Live Traffic data to store (Số lượng nhật ký truy cập): 500-5000 tùy traffic website của bạn, có thể chọn một số bằng 1/4 traffic của bạn.
- Maximum days to keep Live Traffic data (Thời gian lưu trữ nhật ký): 7-14 ngày.
- Traffic logging mode (Chế độ nhật ký traffic): ALL TRAFFIC (Tất cả traffic).
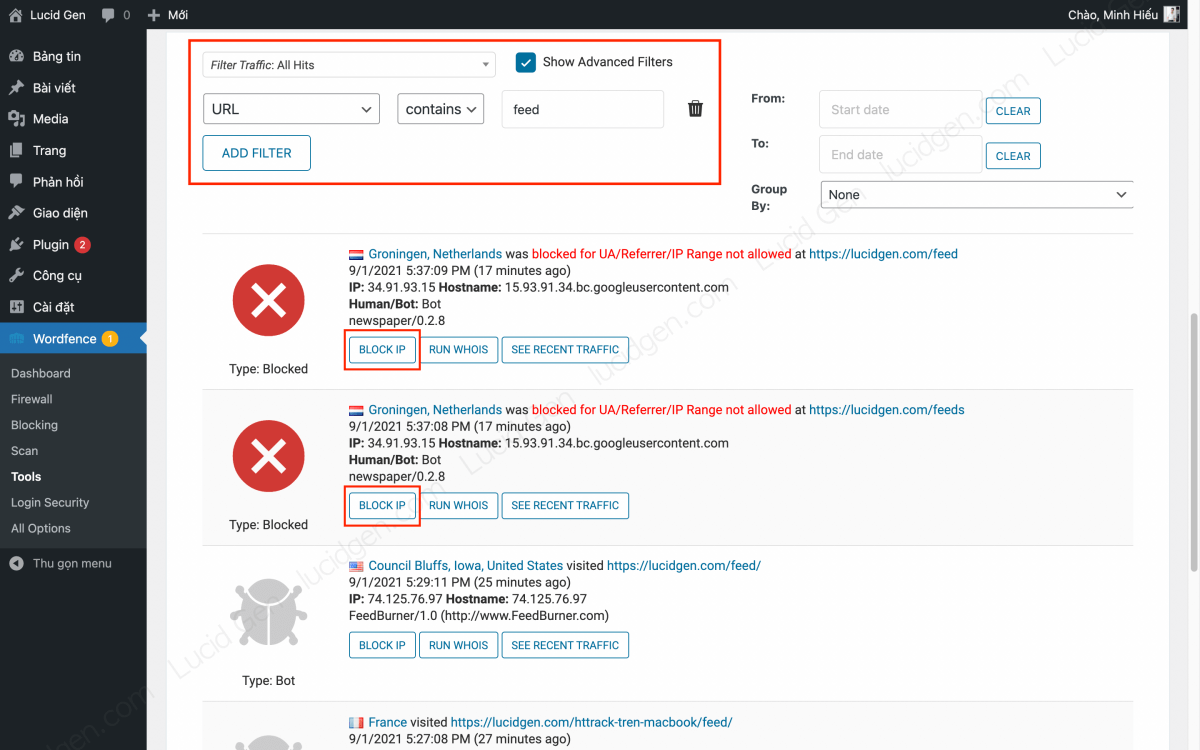
Bước 2: Bạn lọc ra các bot scraping bot để chặn chúng. Bạn nhấp vào Show Advanced Filters > Chọn URL > contains > feed để xem các web scraping bot nào đã truy cập vào RSS của bạn.
Đặc điểm nhận dạng của các web scraping bot như sau:
- User-agent thường là Bot, bạn thấy bot chắc chắn là nó rồi đó. Một số công cụ đánh cắp nội dung có thể tạo ra User-agent là Human (người thường), trường hợp này hơi phức tạp, mình sẽ chỉ ở đoạn dưới.
- Thường xuyên truy cập vào website của bạn với thời gian rất đều đặn, ví dụ như cứ 5-10-15-20-25 phút 1 lần.
- Hostname và User-agent có chứa các từ: feed, content, newspaper…
Lưu ý tránh nhầm lẫn với các scraping bot thân thiện:
- Bot của Google sẽ có Hostname chứa phần đuôi là
googlebot.com,google.com. - Bot của các trang mà bạn đã tạo bookmark hoặc backlink thì tên bot sẽ thường chứa luôn tên website hoặc tên miền website đó, bạn tạo bookmark hay backlink ở trang nào thì bạn nhớ để đối chiếu nhé.
Bây giờ bạn chỉ việc nhấp vào nút BLOCK IP để chặn các web scraping bot này. Để ý đặc hiểm nhận dạng của chúng như dải IP, tên Hostname, tên User-agent để làm thêm các bước nâng cao.
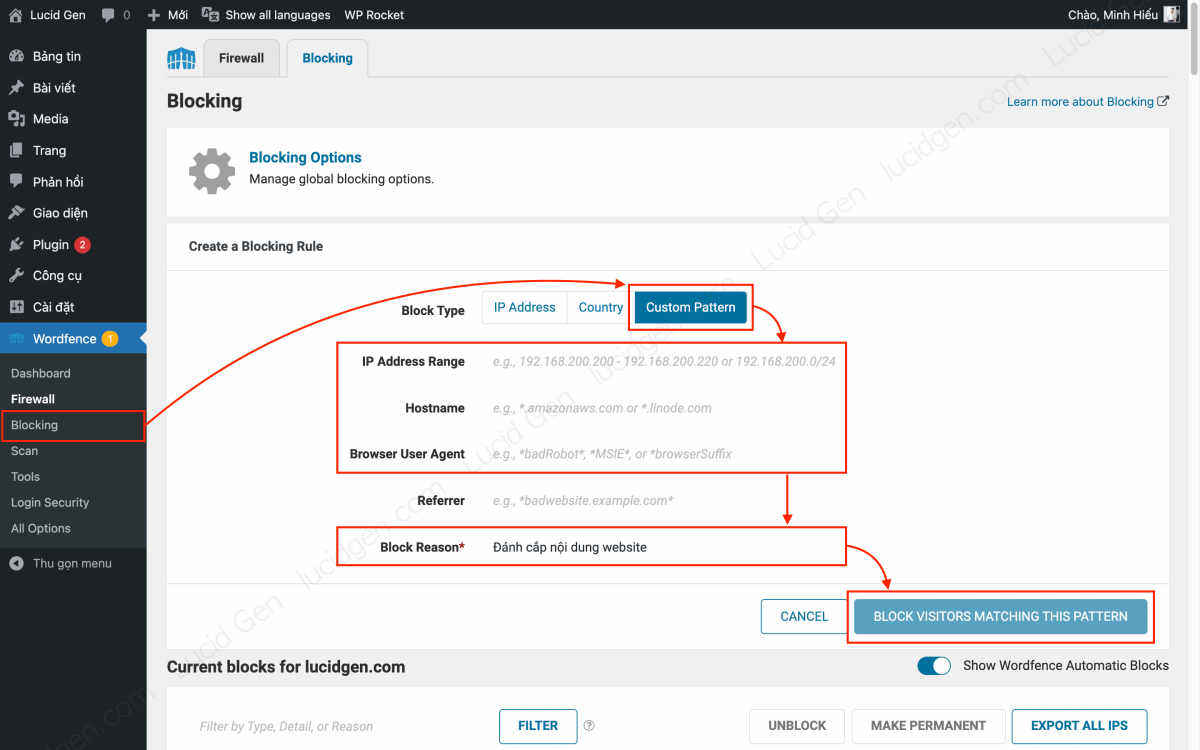
Bước 3: Bạn thêm lệnh chặn các web scraping bot khi có đặc điểm nhận dạng đã biết. Bạn vào Wordfence > Blocking > Custom Pattern vào cấu hình như sau.
Lưu ý: Bạn chỉ điền IP Address Range hoặc Hostname hoặc User-agent cho mỗi lệnh chặn nhé. Điền hết cả 3 thì có nghĩa là phải đúng cả 3 đặc điểm này thì mới bị chặn.
- Block Reason: Đặt một cái tên chung cho bạn dễ nhớ là được, Web scraping bot chẳng hạn.
- IP Address Range: Các công cụ đánh cắp nội dung website thường đổi IP lắm. Bạn hãy chặn nó bằng cách thay số cuối thành 0/24 nhé. Ví dụ IP mà bạn đã block là 192.168.200.200, nó có thể đổi thành 192.168.200.201 để tiếp tục đánh cắp nội dung của bạn, vậy thì bạn hãy chặn 192.168.200.0/24
- Hostname và User-agent: Bạn điền
*từ khóa*, ví dụ có con bot nào mà Hostname hay User-agent của nó thường chứa từ “newspaper” thì bạnh sẽ điền*newspaper*. Hai dấu sao có nghĩa là cho dù phía trước hay phía sau từ khóa này có thêm từ nào hay không thì cũng bị chặn.
Vậy phải làm sao với các web scraping bot có Hostname và User-agent như người bình thường?
- Bạn biết website nào đánh cắp nội dung của bạn đúng không? Hãy tìm IP của các website đó và chặn cả dải IP. Các plugin đánh cắp nội dung website trong WordPress sẽ bó tay với bạn. Thỉnh thoảng bạn kiểm tra lại các website này có đổi sang máy chủ mới hay không để tiếp tục thêm dải IP mới vào lệnh chặn. Kẻ trộm sẽ không vì trộm nội dung của bạn mà sắm nhiều máy chủ đâu, tiền đó để thuê nhân viên viết content còn tốt hơn.
- Dựa vào tần suất truy cập, như mình có nói ở phần đặc điểm nhận dạng, các web scraping bot sẽ truy cập theo thời gian đều đặn 5-25 phút 1 lần. Nếu bạn phát hiện được IP nào có tần suất truy cập như vậy thì hãy chặn dải IP đó. Trong phần Live Traffice bạn nghi ngờ IP nào thì nhấp vào SEE RECENT TRAFFIC để xem tất cả traffic của IP đó có giống bot không.
Trì hoãn cập nhật RSS
Cách này Lucid Gen thấy đơn giản mà hiệu quả với dạng đánh cắp nội dung thông qua RSS. Mục tiêu là để cho kẻ trộm index sau bạn, mà index sau thì Google biết là sao chép của bạn rồi.
Bạn chèn đoạn code này vào trong file functions.php của giao diện. Sửa số và đơn vị tính thành khoản thời gian trì hoãn cập nhật RSS mà bạn muốn. Ví dụ trong code này là trì hoãn 12 giờ, nếu website của bạn index chậm thì bạn có thể tăng lên vài ngày.
//Delay RSS Feed by LucidGen.com
function publish_later_on_feed($where) {
global $wpdb;
if ( is_feed() ) {
$now = gmdate('Y-m-d H:i:s');
$wait = '12'; // integer
$device = 'HOUR'; //MINUTE, HOUR, DAY, WEEK, MONTH, YEAR
$where .= " AND TIMESTAMPDIFF($device, $wpdb->posts.post_date_gmt, '$now') > $wait ";
}
return $where;
}
add_filter('posts_where', 'publish_later_on_feed');
Lucid Gen biết bạn sẽ tự hỏi “vậy thì tăng lên vài tháng hoặc tắt luôn RSS có phải ngon hơn không?” (vì mình cũng từng nghĩ như thế mà).
Nhưng bạn không nên làm vậy, trong phim hay có câu “Rút dây động rừng”. Cứ để kẻ trộm dùng cách đơn giản thì bạn ngăn chặn cũng đơn giản. Nếu chúng vào RSS không được hoặc thấy thiếu quá nhiều bài mới đang có trên website của bạn, chúng có thể nghi ngờ và tìm cách nào đó PRO hơn thì bạn mệt mỏi hơn đấy.
Hãy nhớ mục tiêu của cách này là để cho những trang sao chép nội dung của bạn thông qua RSS phải index sau bạn.
Rút ngắn nội dung trong RSS
Cách này thì xưa rồi, web scraping bot bây giờ đã tự truy cập vào bài viết để đánh cắp nội dung chứ không phải chỉ lấy từ trong RSS nữa. Nhưng mà bạn cứ cài đặt cho nó đầy đủ vậy. Bạn vào Settings > Reading và chọn chế độ Excerpt nhé.

Random class trong HTML trang nội dung
Cách này mình nghe các cao nhân trong các hội nhóm bình luận. Chứ còn làm sao thì mình cũng chưa làm được. Random class trong HTML thì không khó, nhưng phần CSS cũng random theo thì khó đấy. Đây là giải pháp mạnh chống được dạng ăn cắp nội dung từ HTML. Ví dụ như Facebook, Google cũng đang sử dụng random class.
Thêm nhiều liên kết nội bộ trong nội dung
Cách này thì dễ làm, khi viết bài bạn hãy chèn nhiều liên kết nội bộ có liên quan đến nội dung chính. Mục đích chính là để người đọc tham khảo thêm thông tin từ bài viết khác nhưng hỗ trợ cho bài viết chính. Mục đích phụ là làm giảm chất lượng nội dung sau khi bị đánh cắp.
Sau khi đánh cắp thì kẻ trộm thường xóa liên kết nội bộ của bạn. Vậy bạn hãy tưởng tượng xem, có những phần trong bài viết gốc chỉ dẫn cho người đọc xem thêm một bài viết khác để có thêm thông tin, thì bài viết được đánh cắp lại không có các liên kết này. Người đọc sẽ khó chịu và có thể nhận ra đây là nội dung bị đánh cắp. Về tổng thể thì sức mạnh của backlink nội bộ trong bài viết bị đánh cắp không bằng bài viết gốc, nên không hỗ trợ SEO bằng bài viết gốc được.
Thêm watermark (logo) vào hình ảnh
Nếu bạn để ý, bạn sẽ thấy tất cả hình ảnh trên website Lucid Gen đều có watermark. Nếu kẻ trộm sử dụng ảnh gốc của bạn thì chẳng khác nào đang quảng bá website giùm bạn. Cách làm thì rất dễ, mình đang dùng công cụ để chèn logo vào ảnh hàng loạt trước khi tải lên website.
Lưu ý quan trọng, “đừng chèn logo vào một góc”. Những kẻ trộm sẽ chèn logo của chúng to hơn và đè lên logo của bạn, hoặc là chúng sẽ cắt bỏ phần có logo của bạn luôn. Chèn làm sao mà không ảnh hưởng nhiều đến người dùng nhưng làm cho kẻ trộm không thể nào che dấu được logo của bạn nhé. Chèn như Lucid Gen cũng được nè, các trang hình ảnh như ShutterStock, Freepik thì họ cũng làm vậy đó.
Sử dụng DMCA và tố cáo các trang vi phạm
Nhiều bạn bảo là dùng DMCA làm gì, tụi nó vẫn đánh cắp nội dung như thường, lại còn cho DMCA backlink miễn phí. Nghe có vẻ hợp lý nhưng không thuyết phục được mình.
- Bạn cho DMCA backlink: DMCA cũng cho bạn lại backlink mà, bạn cũng có thể sửa code thành nofollow nếu bạn thích, nhưng nofollow thì làm sao bot của Google đi qua đó để lấy backlink cho bạn. Vì thế đừng ít kỷ quá.
- Bạn vẫn bị đánh cắp nội dung: Đúng rồi, DMCA chỉ giúp bạn ở khâu tố cáo thôi.
- Tố cáo lên Google thì không cần DMCA: Chưa đúng, một số trường hợp Google sẽ yêu cầu bạn cung cấp thêm bằng chứng để thuyết phục. Cái đơn giản nhất để bạn gửi cho Google là liên kết DMCA đó. Mình từng tố cáo 180 URL sao chép nội dung của Lucid Gen trong 1 đơn tố cáo, Google đã yêu cầu mình cung cấp thêm chứng cứ, mình đã gửi liên kết DMCA cho Google và sau đó 180 URL đó đã bị xóa khỏi kết quả tìm kiếm. Có nhiều cách để DMCA giúp bạn (chẳng hạn như tố cáo lên nhà cung cấp hosting, áp dụng với nước ngoài), cơ bản nhất thì nó cũng cho Google thấy thời gian bảo vệ bài viết của bạn cao hơn của bên ăn cắp, hoặc nếu bên ăn cắp không có DMCA thì nó thua luôn.
Nên dùng DMCA, miễn phí cũng được, nâng cấp lên Pro càng tốt (Pro để kẻ trộm và Google cảm thấy bạn “không phải dạng vừa đâu” và có thêm vài tính năng khác).
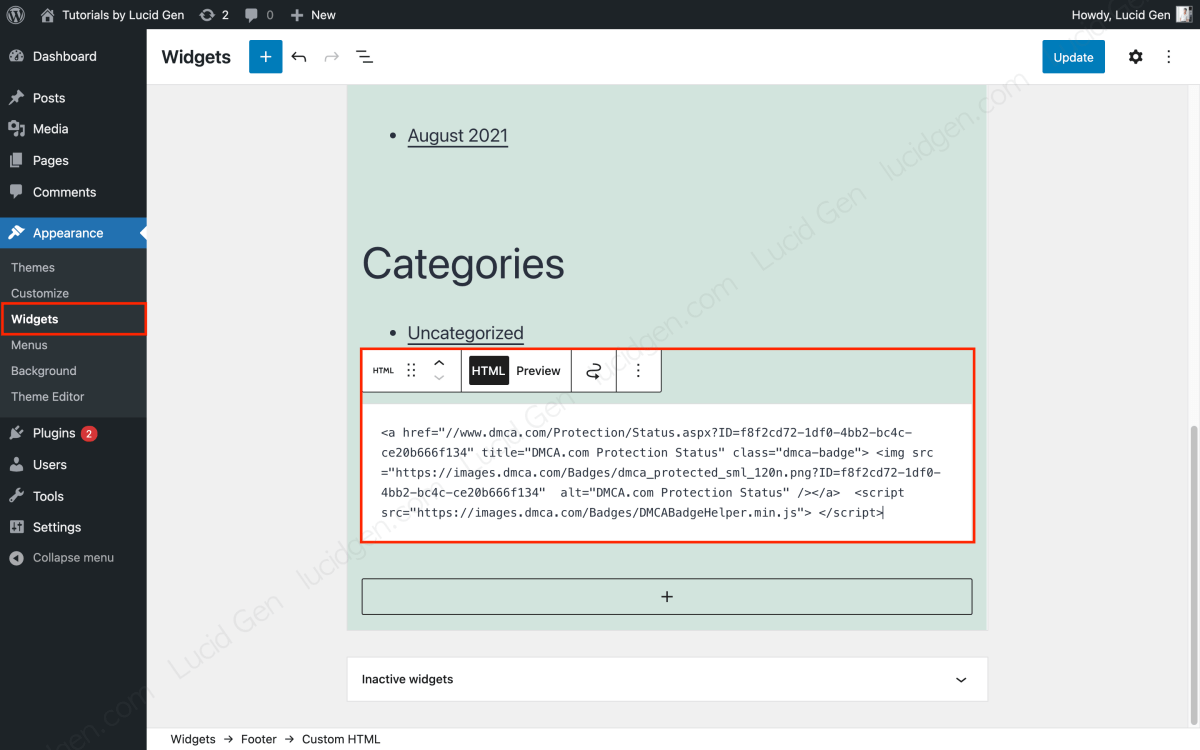
Bài viết này mình không nói thêm về DMCA quá nhiều, bạn hãy truy cập dmca.com để tạo một tài khoản > lấy mã DMCA > quay lại WordPress > Appearance (Giao diện) > Widgets để thêm mã DMCA vào chân website của bạn.
Cuối cùng, nếu bạn đã quyết tâm tố cáo thì hãy xem cách gửi báo cáo vi phạm bản quyền DMCA đến Google và làm theo hướng dẫn từng bước. Tuy nhiên không phải lúc nào đơn tố cáo của bạn cũng được duyệt, còn tùy theo yêu cầu của phía Google team và bạn trả lời có đáp ứng đủ yêu cầu của họ hay không nữa.
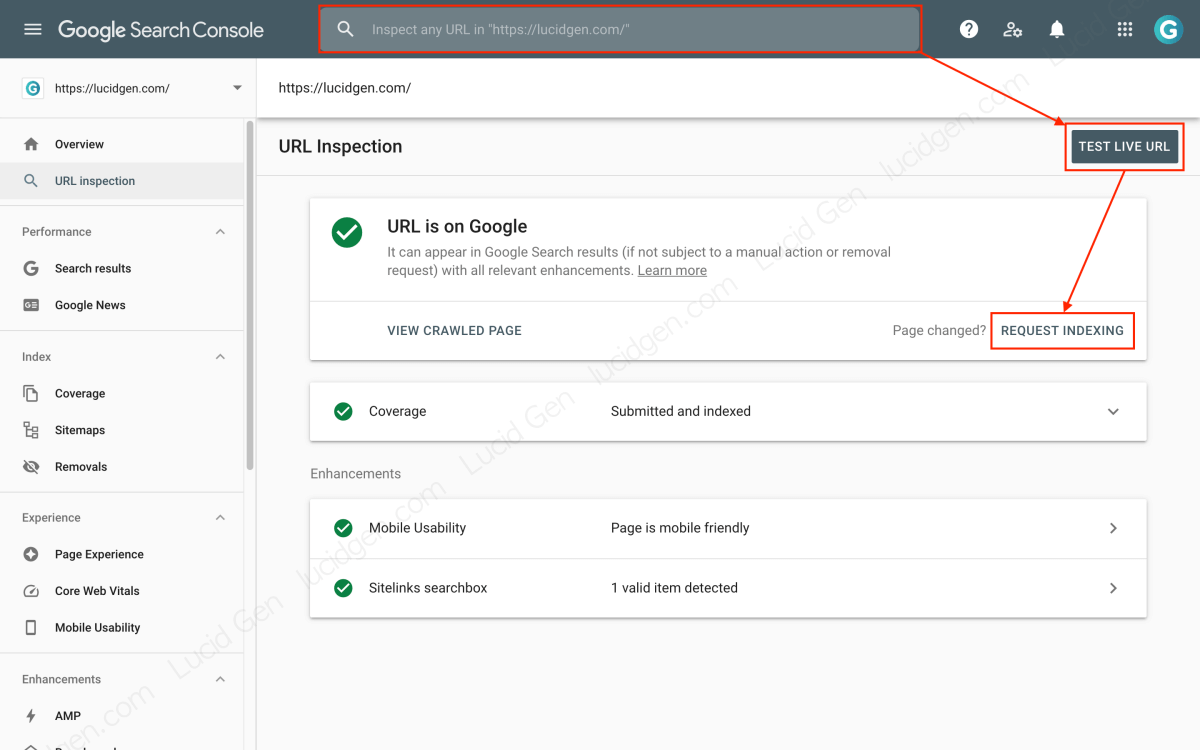
Yêu cầu Google Index nội dung mới ngay khi đăng
Đây là vấn đề quan trọng, bạn phải khai báo cho Google biết bài viết mới của bạn ngay khi bạn vừa đăng nó. Bạn truy cập vào Google Search Console > Dán URL bài viết mới vào ô tìm kiếm > Kiểm tra URL > Yêu cầu index.
Sử dụng tên riêng thay vì “tôi” và “mình”
Bạn hãy sử dụng tên riêng của bạn hoặc tên thương hiệu website của bạn nhiều hơn, thay vì chỉ dùng các đại từ nhân xưng như “tôi” và “mình”. Điều này giúp cho người đọc nhận ra đây là nội dung lấy từ website của bạn nếu như kẻ trộm quên sửa lại nội dung.
Lời kết
Nếu áp dụng hết các kỹ thuật trên thì Lucid Gen tin là nạn đánh cắp nội dung trên website của bạn sẽ được giảm đáng kể. Nếu bạn có cách nào hay, hãy chia sẻ với Lucid Gen nhé.





Cảm ơn bài viết của bạn nhé. Mình có làm các website về vệ sinh công nghiệp mà cứ lên top y rằng 1 thời gian thi nhau các bên lấy nội dung của bên mình về. Xong website của mình cũng tụt hạng luôn. Có khi đang top 1-3 xong mất index :((. Hoặc tụt sâu xuống các vị trí bên dưới. Lắm lúc cay lắm mà không làm gì được. Vào report DMCA xong có lúc mình cũng mất index????
Haizzz. Cảm ơn bạn đã cho mình một vài ý tưởng hay để giảm nạn ăn cắp nội dung
hơi buồn là bài nói về php và wordpress là chủ yếu 🙁 không biết các server dạng nodejs có bị copy không nhỉ ? nếu có thì mong anh update theo dạng chung chung các server dạng khác học theo ạ, gần như các cách ấy đều dùng với wordpress nên cũng khó làm theo. Cơ mà lên mạng tìm cũng nhanh thôi :v chung lại thì bài post hữu ích, mình tìm được bài này thông qua bing AI đó =)))
Chào Hiếu, thật sự thì bài chia sẻ này chỉ là hướng làm, còn làm thế nào thì mỗi nền tảng phải tìm công cụ có chức năng tương tự, biết là hơi khó. Mình không phải chuyên gia code web nên chỉ biết dùng WordPress vì nó có sẵn một số thứ hữu ích. Ngay cả website mình đây làm đủ thứ hết, nhưmg họ vẫn copy rất như thường, họ làm tay thì chịu. Mong là Google sẽ thông minh hơn, biết bài nào là bài gốc.
Em hỏi chút, trước là DMCA em mua, giờ em muốn dùng nó bản free thôi thì có cách nào web nó được duyệt link dmca cũ không ạ? vì e thấy nó cứ báo không thể thấy bảo vệ dmca trên trang e đã setup trước đó :(( cho các link mới và bắt xác nhận lại. và thanh toán
Chào Linh, bạn phải dùng đúng tài khoản DMCA cũ thì mới được nha.
Mình từng mua rồi không mua nữa nhưng link nó vẫn vậy thôi à. Gần đây mình mua lại.
Nói chung là copy là một trò rất bẩn, chúng ta ko nên copy hehe. Mình cũng bị copy nhiều nhưng chủ yếu toàn copy bằng tay
Nếu họ copy hoài thì report thôi bác.
Trước bỏ bê blog quá nên kệ. Giờ mà bị copy phải report ngay. Đã lười viết, mãi mới lấy hơi viết đc bài mà bị copy, nghĩ cay 😀
Thắng Report bọn chúng bằng cách nào vậy. Hix mình mới check thì thấy tụi nó copy y xì nguyên cả web mình luôn, từ hình ảnh lẫn nội dung ngay cả cái mst nó còn ko cả sửa để của mình nhưng thay số đt và tên công ty. thật sự không còn gì để nói nữa buồn ghê.
Bạn xem bài viết cách report Google DMCA nhé
bài viết này hữu ít nhất
Mình rất vui khi thấy bình luận của Phong