
Any website can have its content stolen, and this problem is increasingly common as content theft tools become more advanced. Many website owners have headaches because so much of their effort and brainpower is stolen by others, and the infringing article is even ranked higher than the original website, thanks to that content. In this article, Lucid Gen will share some ways to prevent prevent web scraping, which frustrates thieves and makes them want to give up.
It would help if you read before deciding
Initially, when your website content is stolen, you will often be anxious to find a way to prevent it altogether. But you should know that “radical” is impossible. Please read through the content below to understand the nature of the problem and choose the appropriate course of action.
What is web scraping?
Web scraping is the process of collecting and extracting data from a specific website to serve the purposes of the user of this tool. Good purposes usually capture information, but many evil people have used this method to steal other people’s website content.
This work is performed continuously by web scraping bots every day, hour, and minute to discover the latest content and bring it to users quickly. It is difficult for regular website owners to detect this scraping bot, but Lucid Gen will show you how to identify them.
Why do they steal your website content?
There are many reasons, but the most common is “don’t want to work but want to eat”. They want traffic but are too lazy to brainstorm articles and don’t have money to hire good content staff, so they quickly steal other people’s brainpower.
The second type is to go to “teachers” who teach courses to make money by “Auto blogging”. Put it bluntly, create a website, install a few plugins to steal article content from other websites, and then wait for money from Adsense. If you see these classes, please leave and become human. It’s not that easy, my friend.
There are some other types, too. But rest assured, the ending is usually not good. A website specializing in copying other websites’ content will be rated very low by Google and may not even be approved by Adsense. After a long time of copying, it becomes a habit, and later on, they won’t be able to create anything; they will always be behind you.
How do they steal?
According to Lucid Gen’s research, three popular types of website content theft exist. I will arrange them from easiest to prevent to most difficult to control.
Steal content using RSS
Web scraping bots will access your RSS feeds to discover the latest posts. It will then go to that new article to extract the content on your website and bring it to its server. RSS feeds usually look like this:
https://domain.com/feed(WordPress is this type)https://domain.com/feedshttps://domain.com/rss
This form of website content theft is straightforward to prevent; you need to delay RSS updates and block the IP of web scraping bots, and you’ll be fine. More specifically, Lucid Gen will clarify below.
Steal content using HTML
Web scraping bots will visit your blog and article categories and analyze the HTML to discover new articles.
For this type of website content theft, web scraping bots do not access RSS feeds, so it will be more difficult for us to detect them. But there is also a way Lucid Gen will explain more clearly in the prevention solution section.
Stealing content manually
In this form, website content thieves are more “industrious” and will “Copy Paste” by hand. If this happens, it cannot be prevented with tools. There is only one way: to be more “diligent” than the thief, add more internal links, insert watermarks into photos, and use more personal names…
Editing the content, editing the name, and deleting the link is easy for them (sometimes they forget to edit it), but recreating an image suitable for the content without a watermark will be difficult.
Potential benefits of content theft
Lucid Gen wants to share with you a different perspective on this issue. In many cases, stolen content also benefits the original website.
Google values your website highly
A website whose content is copied by other websites means that the website certainly has excellent and valuable content for users. Google can know which is the original article and which is the page that copied the content. So, don’t worry too much if they steal your website content but don’t get your ranking position.
Watch for a while; just let them steal until you see signs of them taking a ranking position with you, then take action. Imagine that 30-50% of their website content is copied from you. If you act once and make them lose that 30-50%, it’s better than just 1-2 articles, right?
Get backlinks from competitors
Some places copy the content but keep your internal links intact. Maybe they forgot to delete or intentionally left them to please each other. So, you accidentally got more backlinks.
If they do not provide a backlink to your website, try sending a request to insert the link of your original article on their website. If they agree, you have a backlink; if they do not, we will take action.
Should I use a manual copy protection plugin?
In Lucid Gen’s opinion, it shouldn’t be. For many reasons, as follows:
- 99% of your traffic is regular users, and only 1% are manual thieves. Don’t make it difficult for the remaining 99% of users because of this 1%. Sometimes, people need to copy content and images from your website for better purposes, such as learning or instructing friends.
- Lucid Gen also feels uncomfortable visiting sites that do not allow copying or right-clicking. I think that these websites’ owners are a bit unscrupulous.
- Install a utility like Enable Copy to turn off the copy prohibition feature quickly. Ordinary people don’t know, but people specializing in stealing content know everything.
- Make your website heavier.
So don’t install plugins that block content copying. It doesn’t work against thieves; it just annoys users.
How to prevent web scraping
Going through the above section, you probably understand the problem of stealing website content. To whatever extent this problem seriously affects your website, choose the appropriate solution according to that level. Or it’s best to use all solutions at the same time.
Lucid Gen affirms that it cannot help you “thoroughly” handle this problem. But if you apply all the measures below, website content theft will decrease for your website. If there are new effective measures, I will update this article.
Block IP of web scraping bots
To do this, you must use Wordfence Premium. We will ask Wordfence to record the history of the IP, Hostname, and User-agent who has accessed your website. From there, filter out web scraping bots to block them.
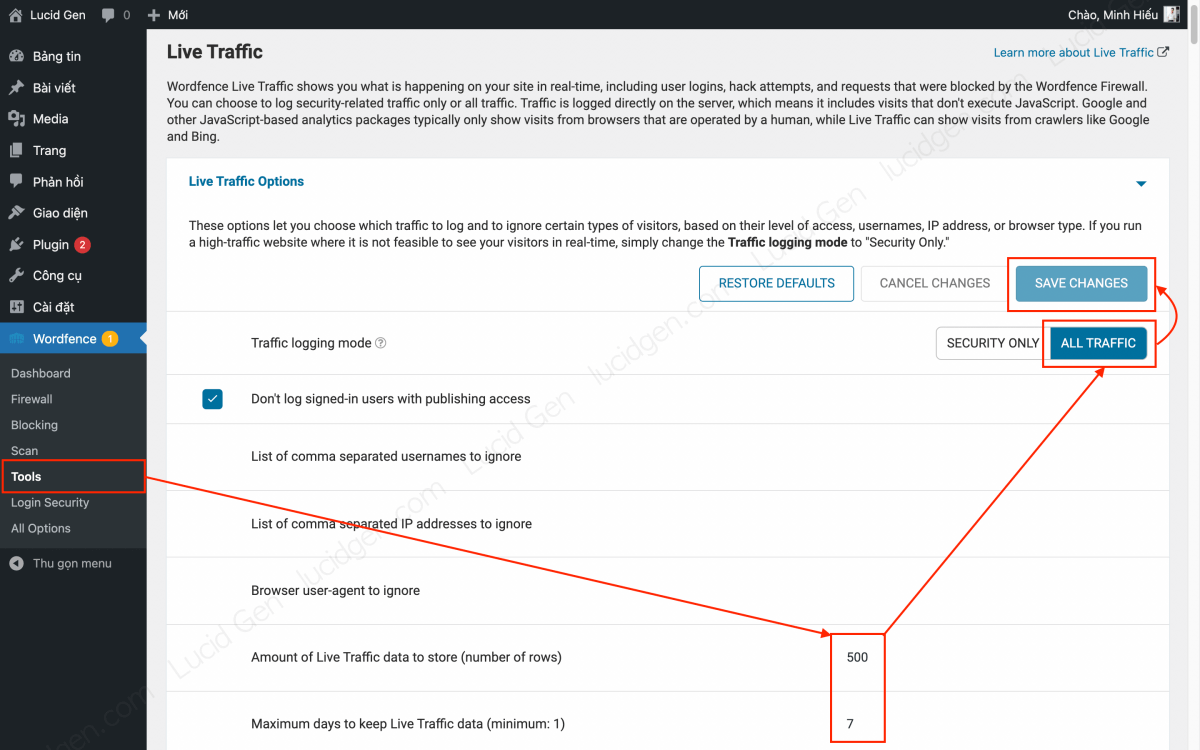
Step 1: You install Live Traffic mode. Go to Wordfence > Tools and install as follows.
- Amount of Live Traffic data to store: 500-5000; depending on your website traffic, you can choose a number equal to 1/4 of your traffic.
- Maximum days to keep Live Traffic data: 7-14 days.
- Traffic logging mode: ALL TRAFFIC.
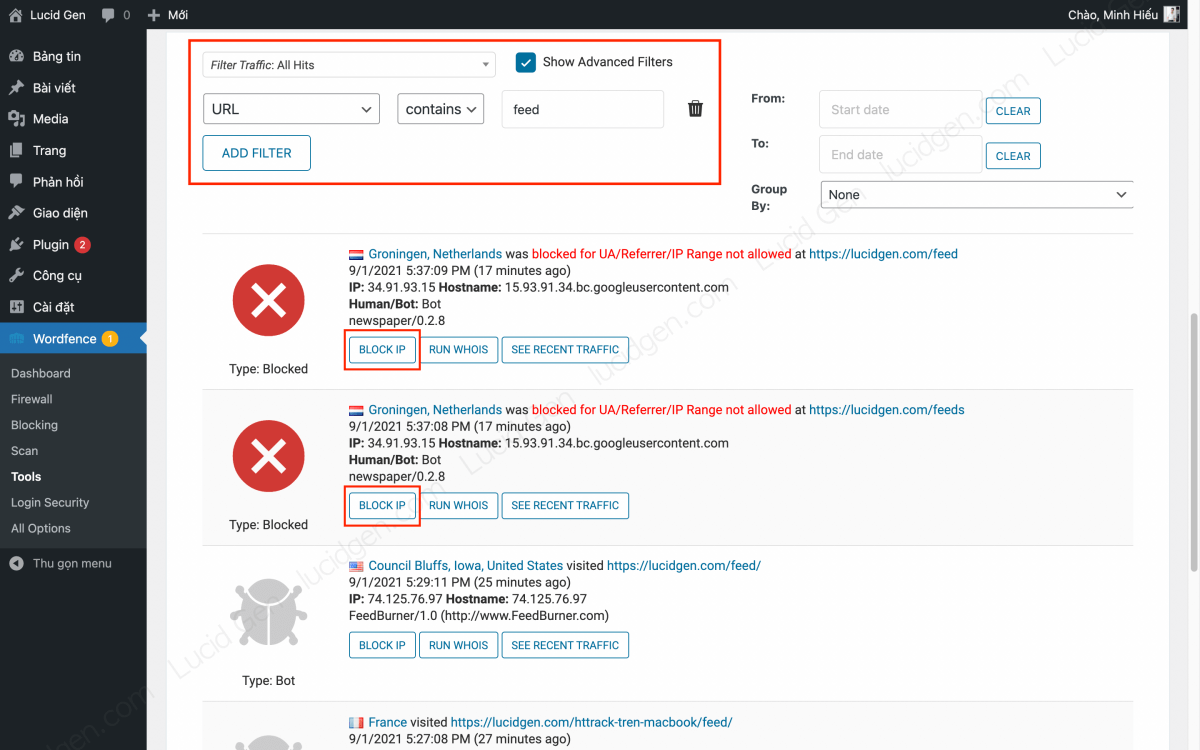
Step 2: You filter out scraping bots to block them. Click Show Advanced Filters > Select URL > contains > feed to see which web scraping bots have accessed your RSS.
Identifying characteristics of web scraping bots are as follows:
- The user-agent is usually a Bot. Some content-stealing tools can create a Human User-agent (ordinary person). This case is a bit complicated; I will show it below.
- Regularly visit your website, for example, every 5-10-15-20-25 minutes.
- Hostname and User-agent contain the words feed, content, newspaper, etc.
Note to avoid confusion with friendly scraping bots:
- Google’s bot will have a Hostname containing the suffix
googlebot.com,google.com. - Bots of pages where you have created bookmarks or backlinks will often contain that website’s website name or domain name. Remember which page you created the bookmark or backlink on for comparison.
You must click the BLOCK IP button to block these web scraping bots. To take more advanced steps, please pay attention to their identification characteristics, such as IP range, hostname, and user agent name.
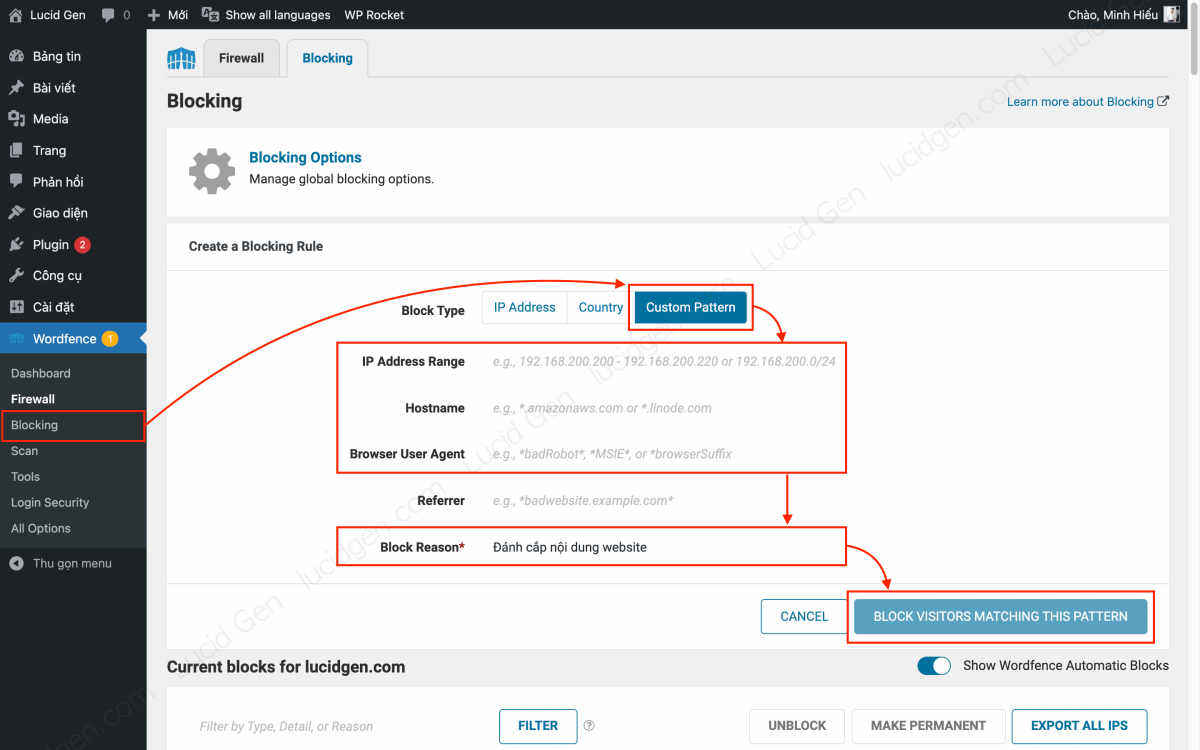
Step 3: You add a command to block web scraping bots when they have known identifying characteristics. Go to Wordfence > Blocking > Custom Pattern and configure as follows.
Note: You only need to fill in the IP Address Range, Hostname, or User-agent for each blocking command. Filling in all three means that all three characteristics must be correct to be blocked.
- Block Reason: It’s okay to give yourself a general name that’s easy to remember, for example, a web scraping bot.
- IP Address Range: Website content-stealing tools often change IPs. Please block it by changing the last number to 0/24. For example, the IP you blocked is 192.168.200.200, it can change to 192.168.200.201 to continue stealing your content, then block 192.168.200.0/24
- Hostname and User-agent: You fill in
*keyword*, for example, if there is a bot whose Hostname or User-agent often contains the word “newspaper”, you will fill in*newspaper*. Two asterisks mean that whether there is any additional word before or after this keyword, it will be blocked.
So, what do you do with web scraping bots with hostnames and user-agents like normal people?
- You know which website steals your content, right? Find the IP of those websites and block the entire IP range. Plugins that steal website content in WordPress will give you up. From time to time, you can check whether these websites have changed to new servers or not to continue adding new IP ranges to the blocking order. Thieves won’t buy a lot of servers to steal your content. That money would be better spent hiring content writers.
- Based on the frequency of access, as I mentioned in the identification characteristics section, web scraping bots will access regularly every 5-25 minutes. If you detect any IP with such access frequency, block that IP range. In the Live Traffic section, if you suspect an IP, click SEE RECENT TRAFFIC to see if all traffic of that IP looks like a bot.
Delay RSS updates
Lucid Gen finds this method simple but effective in stealing content via RSS. The goal is for the thief to index after you; after indexing, Google will know that it is copied from you.
You insert this code into the functions.php file of the interface. Change the number and unit to the RSS update delay time you want. For example, in this code, the delay is 12 hours. You can increase your website index by a few days if your website index is slow.
//Delay RSS Feed by LucidGen.com
function publish_later_on_feed($where) {
global $wpdb;
if ( is_feed() ) {
$now = gmdate('Y-m-d H:i:s');
$wait = '12'; // integer
$device = 'HOUR'; //MINUTE, HOUR, DAY, WEEK, MONTH, YEAR
$where .= " AND TIMESTAMPDIFF($device, $wpdb->posts.post_date_gmt, '$now') > $wait ";
}
return $where;
}
add_filter('posts_where', 'publish_later_on_feed');
Lucid Gen knows you’ll wonder, “Wouldn’t it be better to increase it for a few months or turn off RSS altogether?” (because I also thought like that).
But it would help if you didn’t do that; in the movies, there is a saying, “Unplug the rope to stir up the jungle”. Just let the thief use simple methods, and it will be simple for you to prevent them. If they can’t access RSS or see too many new articles missing on your website, they may get suspicious and find a more PRO way, making you more tired.
Remember, this method aims to get sites that copy your content via RSS to index after you.
Shorten content in RSS
This method is old; web scraping bots now access the article to steal content, not just from RSS. But you can install it fully. Go to Settings > Reading and select Excerpt mode.

Random class in HTML content page
This way, I heard the comments from the experts in the groups. But as for what to do, I still can’t do it. Random class in HTML is not challenging, but random CSS is difficult. This is a robust solution against content theft from HTML. For example, Facebook and Google also use random classes.
Add more internal links to the content
This method is easy to do. When writing an article, insert many internal links related to the main content. The primary purpose is for readers to refer to additional information from other articles but support the main article. The secondary purpose is to reduce the quality of the content after it is stolen.
After theft, thieves often delete your internal links. So, imagine parts in the original article instructing readers to view another article for more information, but the stolen article does not have these links. Readers will be upset and may realize this is stolen content. Overall, the strength of the internal backlink in the stolen article is not equal to the original article, so it cannot support SEO like the original article.
Add a watermark (logo) to images
If you pay attention, you will see that all images on the Lucid Gen website have a watermark. If a thief uses your original photo, it’s like promoting your website for you. The method is straightforward. I’m using a tool to insert logos into bulk photos before uploading them to the website.
Important note, “don’t insert the logo in a corner”. Thieves will insert their logo larger and over your logo or cut off the part with your logo. Insert it in a way that doesn’t affect users much but makes it impossible for thieves to hide your logo. Inserting like Lucid Gen is also possible; image sites like Shutterstock and Freepik do that.
Use DMCA and report violating sites
Many people ask why we use DMCA; they steal content as usual and even give DMCA backlinks for free. It sounds reasonable but doesn’t convince me.
- You give DMCA backlink: DMCA also gives you a backlink; you can change the code to nofollow if you like, but with nofollow, how will Google bots go through there to get the backlink for you? So don’t be too selfish.
- You still get your content stolen: That’s right, DMCA only helps you at the denunciation stage.
- Reporting to Google does not require DMCA: Not genuine; in some cases, Google will ask you to provide more evidence to convince. The simplest thing for you to send to Google is that DMCA link. I once accused 180 URLs of copying Lucid Gen’s content in a complaint; Google asked me to provide more evidence. I sent the DMCA link to Google, and then those 180 URLs were removed from the search results. There are many ways for DMCA to help you (such as reporting to the hosting provider, which applies to foreign countries). It also shows Google that the protection time for your articles is higher than that of the stealing party, or if the party doesn’t have a DMCA, it loses.
It would help if you used DMCA; it’s free and better to upgrade to Pro (Pro makes thieves and Google feel like you’re “not the right type” and has a few more features).
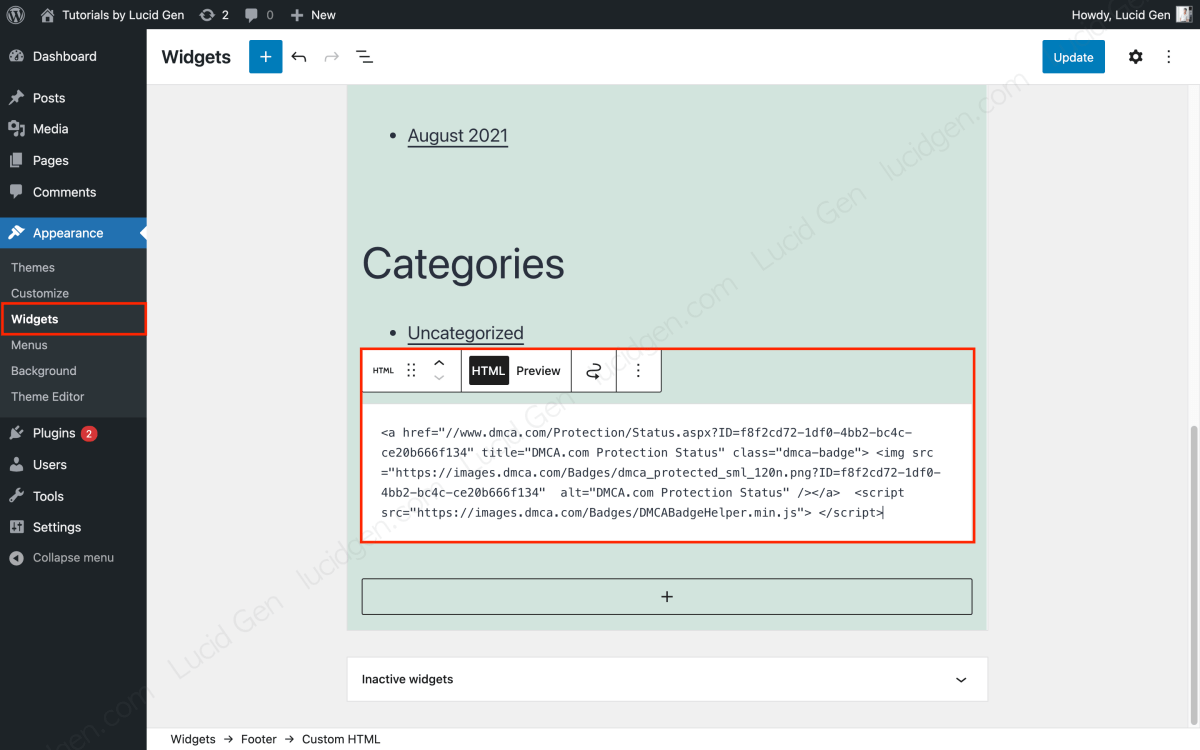
In this article, I won’t talk too much about DMCA. Please visit dmca.com to create an account > get the DMCA code > go back to WordPress > Appearance > Widgets to add the DMCA code to your website footer.
Finally, if you’re determined to report it, see how to submit a DMCA copyright infringement report to Google and follow the step-by-step instructions. However, your complaint will not always be approved; it depends on the requirements of the Google team and whether your response meets their requirements.
Request Google Index new content immediately upon posting
This is important; you must notify Google of your recent article after posting it. You access Google Search Console > Paste the unique article URL into the search box > Check URL > Request index.
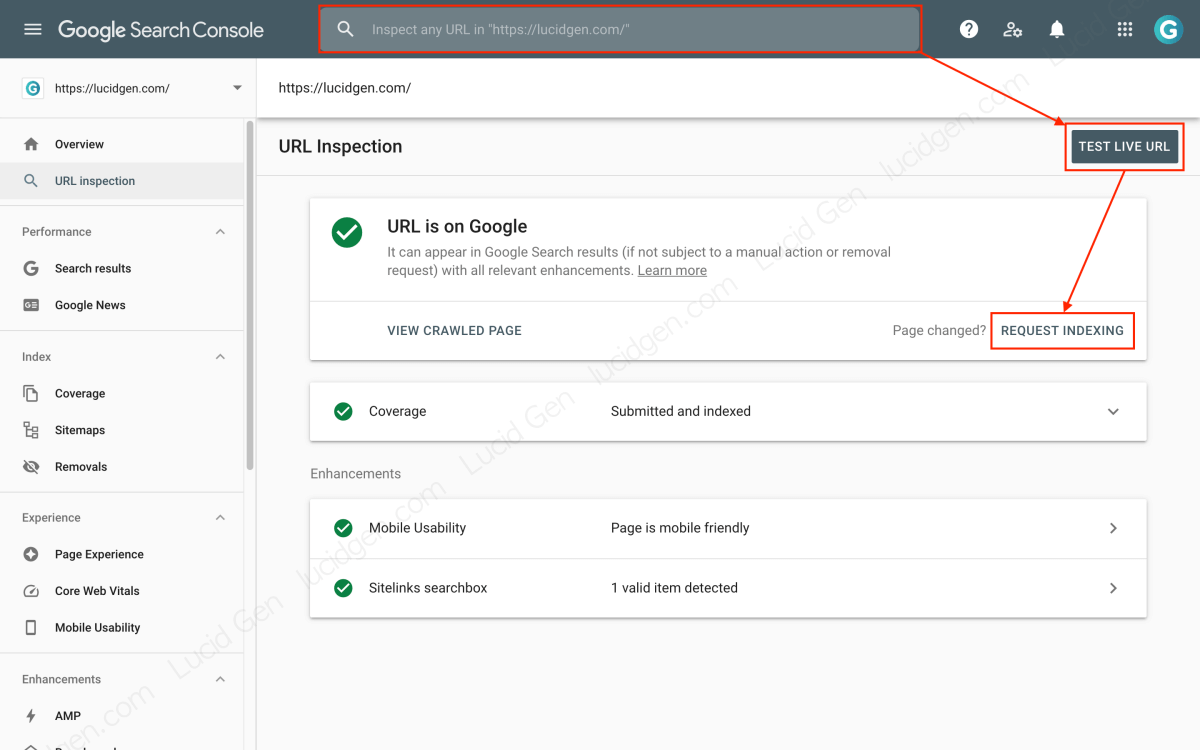
If you use WordPress, please use the Instant Indexing for Google plugin to send an index as soon as you post.
Use your name instead of “I” and “me”
Use your name or your website brand name more instead of using personal pronouns like “I” and “me”. This helps readers realize that this is content taken from your website if the thief forgets to edit the content.
Conclusion
If all of the above techniques are applied, Lucid Gen believes that content theft on your website will be significantly reduced. If you have a good way, please share with Lucid Gen.





